
Fontes não estruturadas de dados
Hoje em dia há muita informação circulando através de meios eletrônicos, esteja ela disponível publicamente em páginas da internet, ou restrita a documentos
produzidos e armazenados nas redes internas das corporações. Tais informações muitas vezes aparecem misturadas ao texto de documentos que não possuem estrutura nem
formato pré-estabelecidos. Estes documentos (ou páginas da internet) cujo conteúdo é livremente formatado e organizado são o que chamamos de fontes não estruturadas de dados.
Mesmo que sejam importantes, contendo dados estratégicos para determinados tipos de negócio, as informações contidas nestes documentos não podem ser facilmente processadas por não estarem
estruturadas de forma adequada.
Uma alternativa bem conhecida para tratar a informação contida em fontes não estruturadas de dados é a indexação dos documentos baseada na ocorrência e co-ocorrência de termos no texto.
Soluções nesta linha já vem sendo oferecidas há algum tempo por motores de pesquisa tais como o Google ou Yahoo. Embora útil em muitos casos, a simples indexação de texto não permite responder
a perguntas cuja resposta dependa de dados comparativos. Por exemplo, quando pesquisamos no Google "qual o nome da empresa que vendeu mais sabonetes em 2010?" a reposta obtida foi
algo como "sabonete causa 471 casos de alergia".
O tratamento da informação não estruturada
A extração de informações consiste essencialmente em demarcar informações contidas em fontes não estruturadas de dados (e.g. texto livre).
Ela difere da simples indexação de texto por ser capaz de classificar, ou seja, "atribuir um nome" à informação encontrada. Além disso, a extração de informações permite separar as informações que
são de particular interesse daquelas informações consideradas irrelevantes, o que não é feito durante a simples indexação de documentos baseada em seu texto.
Uma das dificuldades no processo de extração é justamente identificar quais informações são relevantes e precisam ser demarcadas, pois o conteúdo analisado pode
possuir diferentes subconjuntos de informações que interessem a grupos distintos de pessoas. O ideal é uma solução declarativa e inteligente, através da qual cada grupo possa indicar com
facilidade quais são as informações de seu interesse, e que seja capaz de extrair automaticamente essas informações.
Outra dificuldade na extração é ter as informações extraídas armazenadas num formato e estrutura apropriados para seu processamento. Isso é necessário para que os dados
possam ser facilmente recuperados, pós-processados ou até mesmo submetidos a um processo de mineração de dados para obter informações estratégicas para a inteligência dos negócios. Na
maioria dos casos, a informação extraída precisa ser transferida para sistemas gerenciadores de bases dados (SGBDs) para permitir que seja gerenciada adequadamente.
Há vários tipos de SGBDs no mercado, sendo mais comuns aqueles baseados no modelo relacional (e.g. Oracle Server, DB2, MS-SQL Server, MySQL, PostgreSQL, etc.). Entretanto, transferir a informação
extraída para uma base de dados relacional não é tão simples, pois exige um trabalho adicional de modelagem de dados e criação de scripts para realizar a transformação e a carga dos dados.
A chave para a estruturação e gerência de conteúdo
A plataforma TagmaX © (TAGging autoMAtico em Xml)
disponibiliza uma tecnologia exclusiva para extração de informações capaz de "aprender" quais informações são
importantes e precisam ser extraídas no intuito de atender a necessidades específicas de uma aplicação ou negócio. É uma solução inovadora, que funciona de forma declarativa e automática,
pois elimina a necessidade de escrever regras ou código específico para realizar a extração. Isso significa que ela pode ser utilizada nas organizações sem a necessidade de nenhum conhecimento
prévio sobre quais técnicas de extração existem nem sobre qual a melhor forma de aplicá-las. Além disso, a plataforma TagmaX já incorpora uma tecnologia para armazenamento e
gerência de dados, permitindo que as informações sejam gerenciadas imediatamente após a extração.
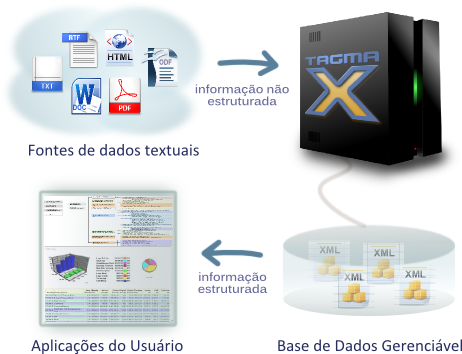
Na plataforma TagmaX, o processo de extração se inicia com a importação de algumas amostras de documentos ou páginas da WEB
para a base de dados do sistema. Estas amostras são então manipuladas através da inserção de tags XML (eXtended Markup Language) no texto para indicar que informações se
pretende extrair. Durante esse processo de preparação das amostras, pode-se inclusive definir se estas informações estarão organizadas em um ou vários níveis por meio de tags
aninhadas.
A marcação introduzida no texto das amostras é aprendida pelo sistema. A partir daí, basta inserir novos documentos ou páginas da WEB na base
de dados para que seu texto seja automaticamente rotulado de acordo com aquela marcação e armazenado na base de dados.
A base de dados TagmaX utiliza o modelo XML. A vantagem da XML é que, além de ser uma tecnologia padronizada, ela permite que tags sejam
embutidas nos documentos para demarcar as informações de interesse sem contudo alterar a estrutura original do texto. Uma vez inseridos na base de dados XML, os documentos ficam automaticamente
estruturados e indexados através de um DOM (i.e. o Document Object Model do modelo XML), podendo ser consultados diretamente através de linguagens padronizadas para manipular conteúdo XML,
tais como a XPath, XQuery e XUpdate. Além disso, os dados XML podem ser facilmente transformados em comandos SQL para alimentar as tabelas de base de dados relacionais
utilizando-se tecnologias como a XSLT.
Um diferencial importante da plataforma TagmaX é que, além de aprender como classificar e demarcar as informações de interesse, ela é capaz de aprender
também hierarquias complexas de marcação de texto a partir de tags aninhadas, o que permite reconhecer estruturas de marcação em múltiplos níveis (e até mesmo recursivas) durante o
processo de marcação automática. Um outro aspecto inovador é a possibilidade imediata de gerenciamento das informações extraídas, de uma forma totalmente integrada a tecnologias já padronizadas.
Até o momento, não se conhece nenhuma outra solução de extração de informações com estas características, o que torna a plataforma TagmaX uma tecnologia exclusiva no
mercado1.
Para obter mais informações, entre em contato com a TagmaTec.